
At the end of October we brought together a number of projects making use of open data standards for policy impact. Together, we explored some of the elements that make for effective open standards. This is the first post in a series capturing some of the learning.
The word ‘standard’ means different things to different people. To policy audiences, a standard is often about describing the information that should be collected, shared or disclosed, or defining best practices to be followed. To the technical community, a standard may be about specifying how data should be structured, represented and exchanged. To expert groups, a standard might be about definitions and measurement. Deploying open standards as a tool for social impact brings together all these elements.
Last week we hosted an event at Space4 (the new co-operative technologists’ co-working space in Finsbury Park) to explore how different social change projects have created and used open standards to achieve their goals. We had presentations on the International Aid Transparency Initiative, 360Giving, Open Referral, Open Repair and Open Contracting: each highlighting shared and contrasting aspects of open data standard design and adoption.
IATI - International Aid Transparency Initiative
Created: 2008
Goals: Better sharing of information on aid projects, budgets and spending
Approach: International initiative with aid donors and recipients involved in governance; XML standard; central registry of data
Adoption: Over 600 publishers; adoption as input or output format for a range of tools
Bill Anderson kicked off our discussions with critical reflections on the longest established standard in the set: IATI.

IATI emerged from a long history of data collection projects in the aid sector, including the 50 year old statistical work of the OECD Development Assistance Committee, and the creation by AidData of a centralised research dataset of projects. It took a different track to these projects, with distributed publication, and a “publish once, use everywhere” philosophy.
Although the project now has over 600 publishers, and has extended data sharing beyond government donors, to include many others in the aid delivery chain, it still faces big challenges in providing the depth and quality of data that partners feel is needed for effective use of the data, and improved aid co-ordination.
Bill suggested much of this may be due to original design flaws in the standard - which did not make a big enough break with OECD systems in order to design around the demand-side, instead of existing data supply. A key challenge since then has been around how to ‘fix’ a standard and recover from earlier bad design choices.
One approach for the future Bill discussed involved a move from monolithic standards to supporting data exchange using smaller building blocks of interoperability. To back this up, Bill called for greater collaboration between standards, citing projects like org-id.guide as a key step forward in developing shared infrastructure to join up across related datasets.
Ultimately though, Bill called on us not to forget the politics. However good the technical approach, if standards can’t connect clearly with real user need, they risk irrelevance.
It was through work on IATI that many of the Open Data Services team first got thinking about the opportunities and challenges of open data standards as tools of mass collaboration, and we are grateful to Bill for a thought provoking start to the evening.
360Giving
Created: 2014
Goals: Supporting (UK) grantmakers to publish their grants data openly, to understand their data and to use the data as part of a more innovative and informed approach to grantmaking
Approach: Independent charity set up by grantmakers. JSON scheme & flat CSV/Excel templates; data quality tool; central registry of data; engagement and capacity building with grantmakers; developing challenge fund to encourage application creation
Adoption: 55+ grantmakers publishing data on over 200,000 grants. Some government adoption also
Next up was Rachel Rank from 360Giving. 360Giving emerged from one funder’s struggle to get the information needed to be strategic about grantmaking. It combines a comprehensive JSON schema behind the scenes with an adoption model based on starting with simple spreadsheets with just the most important fields on the what, why, where, how and how much of grantmaking.
![]()
360Giving is not a transparency campaign: its focus is ultimately on getting data into use. Early on, the project realised that to incentivise data publishers, grantmakers needed to be able to see their data in use, which led to the creation of GrantNav - a basic application for exploring data that has been published, and that meets basic quality criteria. To help publishers understand the quality criteria when preparing their data, the original schema validator has evolved into the 360Giving data quality tool.
Although the full corpus of 360Giving data is not yet comprehensive, the project is on track to cover the majority of funding by value in the coming years, particularly by targeting the largest donors. This focus on coverage increases the utility of the data which is already being used to power tools for grant seekers (BeeHive), and in geographic analysis of grantmaking patterns.
Rachel ended by reflecting on the question of change: exploring how 360Giving has recently established an online community forum (using discourse): moving discussions on potential updates to the standard from their previous location on GitHub to this new space in order to engage a wider community in setting the future path of the standard.
Open Data Services Co-op are the lead technical partner supporting the development and adoption of 360Giving, and built the GrantNav platform.
Open Referral
Created: 2013
Goals: Building the foundation of a healthy information ecosystem for information and referral provision, so that people in need of support can find what they need, wherever they look
Approach: Humanitarian Services Data Specification (HSDS) initially specified using the datapackage spec as a collection of CSV files; now developing an API spec; outreach to vendors to encourage adoption in existing products
Adoption: Pilot implementations by vendors, and bi-lateral data exchange. Open source tools that draw on the HSDS data model
Greg Bloom took the trip from Miami to join us and discuss Open Referral: a project seeking to break down silos in community resource directory data. This is information on services for people in need, from legal advice to homeless shelters and mental health support services. Greg described how the current landscape involves a mess of duplication, manual work and missed connections – and set out the vision of Open Referral to enable streamlined data exchange.
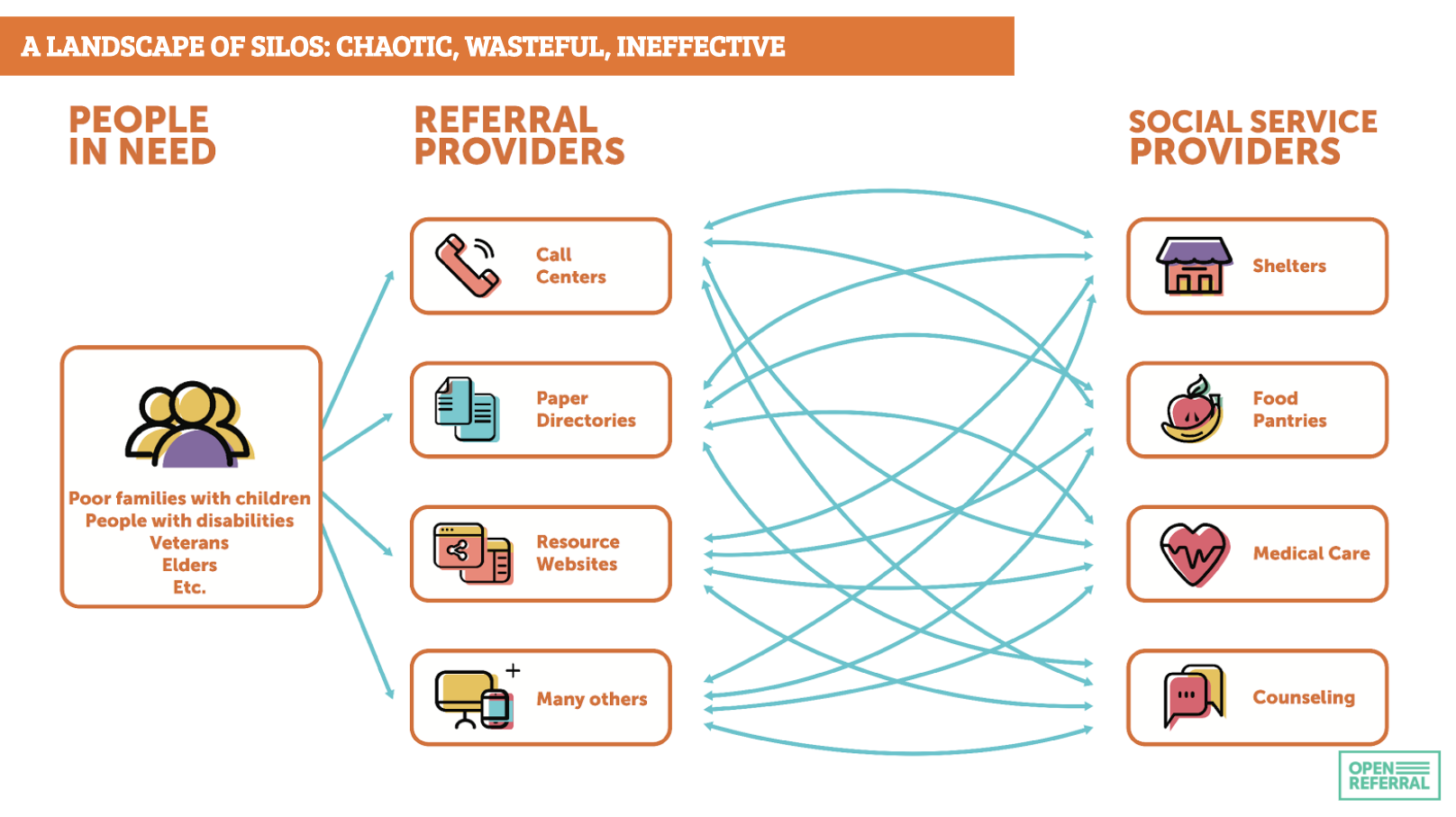
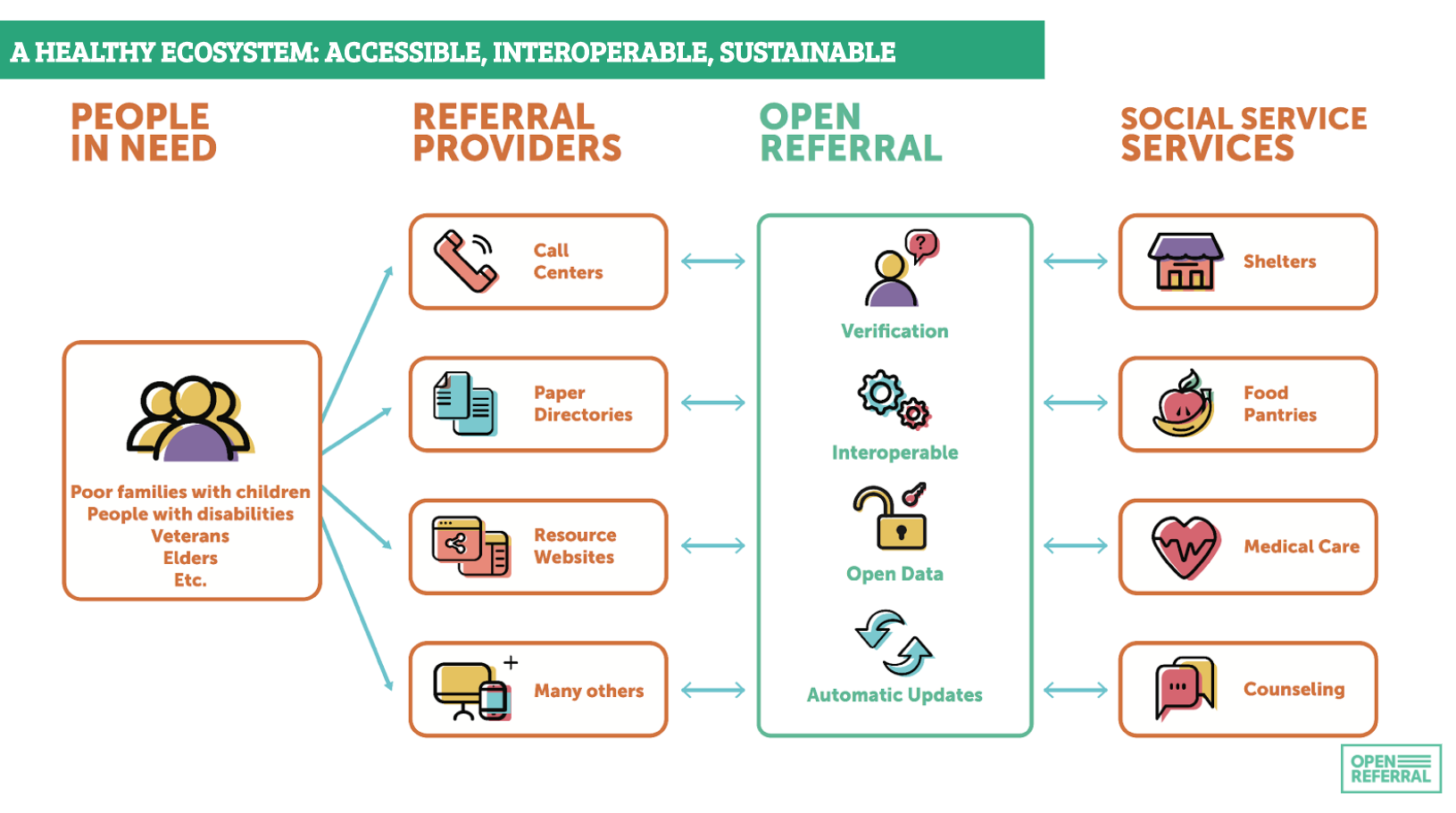
This involves more than just a standard: connecting up constantly changing datasets from different providers will need services for verification, de-duplication and managing automatic updates. But the Human Services Data Specification provides a foundation for this.
One key challenge in HSDS, shared by 360Giving, is around classification. Whilst getting the basic who, what and where of grants and services standardised may be relatively straightforward, gaining consensus on how to categorise them is not. Whilst some standards adopt and promote particular taxonomies, both 360Giving and HSDS currently provide a way for classifications to be shared, but remain agnostic on the particular scheme that is used. Balancing flexibility of classification with user demand for clear ways to filter and navigate data is a key challenge.
Greg also described the importance of developing a business model around an open standard: encouraging organisations who may, to date, have relied on limiting access to their data, to shift to an open data approach – in which value is added by making data accessible, rather than simply holding a dataset.
Open Data Services Co-op have been working to Greg to steward the evolution of HSDS from version 1.0 through to an updated version 1.1 with a central source of schema and documentation.
Open Repair
Created: 2017
Goals: Changing our relationship with electronics and promoting a culture of repairing
Approach: Building a partnership and establishing shared vision and values; setting out basic conceptual model; identifying common codelists
Adoption: Just starting out
Neil Mather introduced the emerging Open Repair standard. Open Repair is a new initiative, bringing together a number of groups from across the world who are working to challenge the throw-away culture around consumer electronics. Born out of a recognition that all these groups are collecting data, yet doing so in different ways, the Open Repair Alliance has been established to encourage alignment of their data collection – opening up new opportunities for analysis, and for advocacy for electronics manufacturers.

The project has started by looking at existing data practices at repair events, from the paper logs used at some UK ‘Restart parties’, to the digital tools used by some partners in the Open Repair Alliance. The discovery of a well maintained hierarchical taxonomy of electronic devices by one of the partners has pointed to the opportunity to collaborate around a common codelist of devices. If the right information is collected on devices, the faults they develop, and the success of fixes, then the Open Repair Alliance may have a resource of great interest to manufacturers who want to understand the post-warranty life of their products.
Neil reflected on the potential for adoption of a standard not only by community groups, but also by small businesses involved in electronics repair.
Right now, Open Repair is at an early stage, and Neil described how, through working with Rob from the Open Data Services team, they’ve been able to split up the development process, starting first with establishing a shared vision amongst standard partners, and from there, building initial conceptual models, before getting down in the development of technical specifications and schema.
Open Contracting
Created: 2013/14
Goals: Value for money, integrity, effective service delivery and level playing field for business in public contracting across the world
Approach: A comprehensive JSON data standard; securing government commitments to adopt at the policy level; supporting adoption through global and regional ‘helpdesks’; continuous learning
Adoption: 15+ governments implementing or working towards adoption; 10+ open source tools implementing aspects of the standard
Our final presentation was from Gavin Hayman, CEO of the Open Contracting Partnership. The OCP describes itself as a ‘silo-busting collaboration’ working to transform transparency, accountability and effectiveness in public contracting. With over $9.5tn spent through public contracts worldwide every year, even small gains can make for a big impact in the use of public resources.
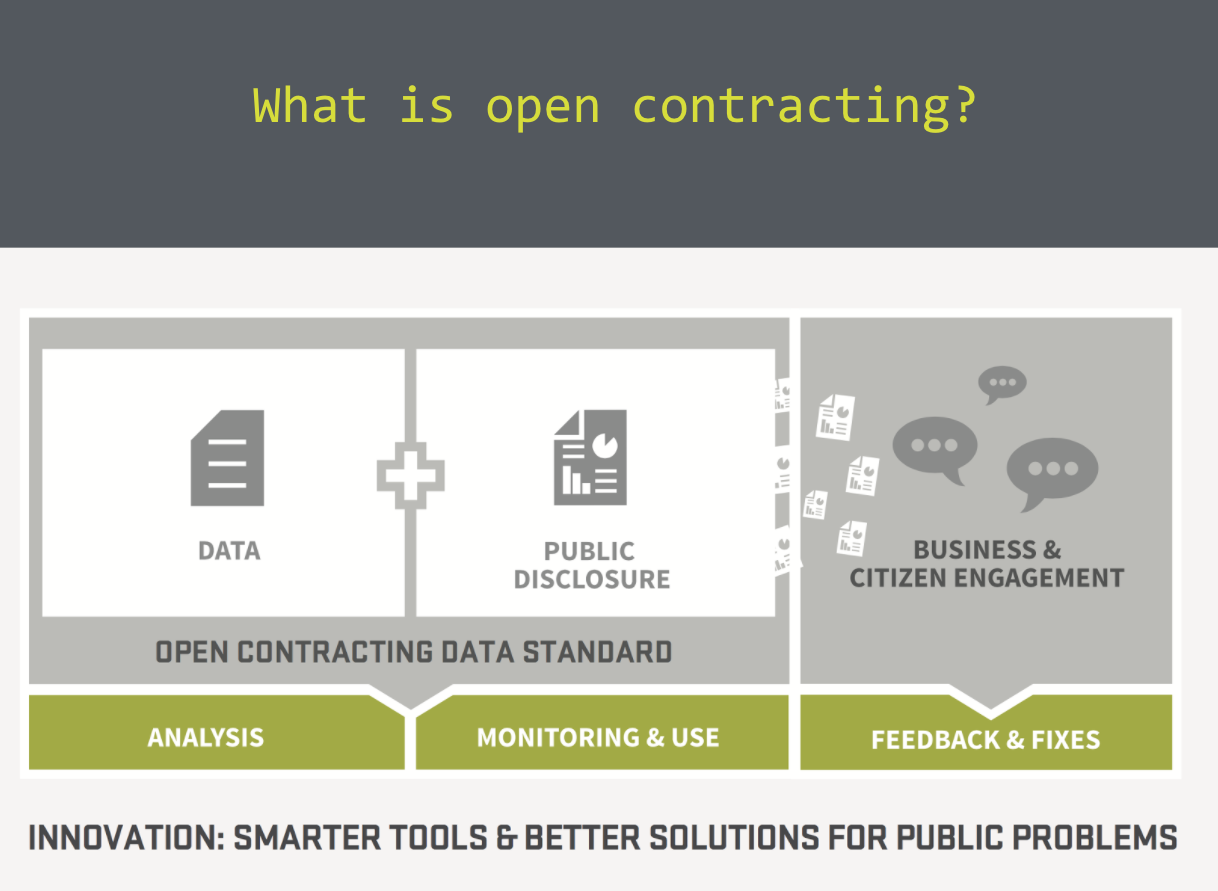
The first version of OCDS was developed through a year-long process, iterating back and forth between focus on data supply, and data demand, and resulting in a set of common schema building blocks, that expand out to around 300 unique fields covering all stages of a contracting process.
Key to the adoption of OCDS since then has been the combination of advocacy and outreach to encourage government adoption, and then the provision of technical assistance and data quality checks through a ‘helpdesk’ service. Gavin described three adoption models that have been emerging, each with different dynamics in terms of securing data, and improving the coverage and quality of the data provided:
1) OCDS used as the data model inside the government e-procurement system (like Prozorro in Ukraine).
2) Data extracted via API from existing government e-procurement system and then the open data visualised on public platforms (as in Mexico at the City and Federal level).
3) No interaction with government procurement system, but instead civil society using OCDS to scrape, structure and analyse information from existing documents (like Budeshi in Nigeria).
Gavin closed by talking about how data is only the start: it’s how it is used that really matters. In the Open Contracting case, the spread of OCDS is supporting the emergence of a range of tools to better communicate contracting, and to calculate metrics for red-flag anti-corruption analysis, or to highlight areas where procurement could be more efficient.
Open Data Services Co-op took on maintenance of OCDS from version 1.0 onwards, and manage the global technical helpdesk.
Conclusions
At first glance, talk of Open Data Standards might sound boring, but when you focus on the impact they aim to achieve, all the hard work on schemas, documentation, validation and codelists feels much more worth it.
Through the talks last week we saw how each standard is different: with an interplay between technology, policy, and community shaping the way they are designed and evolve.
Most of all, though, we learnt of the importance of getting together to critically reflect on open data standards. Although standardisation has a long history, open data standards are a more recent addition to the social change strategy toolbox.
If you would like to get involved in future gatherings – do get in touch!
P.S. You can also read a great write-up of the event from Sam Goeta of DatActivi.st over on medium here.
This post was written as part of the Open Standards for Data project, supported by the Open Data Institute as part of a program of work with Innovate UK, the UK’s innovation agency.