
At Open Data Services, we help people publish and use open data. We’ve been working with 360Giving to help funders publish open data about their grants, and empower people to use this data to improve charitable giving. 360Giving’s vision is to make grantmaking in the UK more informed, effective and strategic.
To make it easy to access COVID19-related grants data, 360Giving has developed the COVID19 Grants Tracker. This pulls and visualises data published by UK funders about their grants made in response to the crisis in the 360Giving Data Standard and is already helping funders to collaborate in unprecedented ways. At the time of publication, the tracker includes over 5000 grants, together worth over £77 million and the numbers are updated daily.
One reason 360Giving could deploy this tracker with daily updates is because we’ve collaborated to build a streamlined and automated data publication pipeline, whose first application is 360Giving’s search engine for grants data, GrantNav.
Why data pipelines matter
While we hadn’t predicted our pipeline would support the COVID19 Grants Tracker when we started the work in 2019, the system was designed to support exactly this kind of tool. The fact our new pipeline was used for such an important use so soon after we went live shows how taking stock and building resilient infrastructure can make open data more useful, usable and in use.
Updating the pipeline has had immediate impacts: we’ve removed the need for developers to fetch all the data before they can start to explore it, and allowed research tools to be built in a matter of hours (rather than weeks) using automatically updated information.
In this blog post, we share how we worked with 360Giving, some of the technical details of the pipeline, and what we’ve learned along the way.
Taking stock
As we spend a great deal of time understanding who uses 360Giving and their needs, we identified two main issues: the manual process of loading data into GrantNav, and the lack of access to a relational database that enables users to explore the data.
No more manual loads
At the start of the project, loading data into GrantNav was a monthly, manual process that required developer time. Funders would publish a spreadsheet using the 360Giving Data Standard on their website, and the data would be fetched, checked and loaded into GrantNav by 360Giving and Open Data Services.
In the early days, these manual loads helped us find errors and build resilience into the system. They gave 360Giving opportunities to understand their data, helped shape guidance for grantmakers, and familiarised our team with the project.
As we now had a better understanding of the data and GrantNav’s role in grantmaking transparency infrastructure, we decided the time was right to automate the pipeline to increase the frequency of uploads and free up developer time.
No more duplicated data fetching
360Giving recognised the importance of a ‘show, then tell’ strategy for open data early on. As well as getting funders to publish and share data, users also need to be able to see and interact with it.
With this in mind, GrantNav was initially created as a data visualisation and access tool in the form of a document store (which is optimised for searching text and casual, human exploring), rather than a relational database (which is optimised for linking entries together, and for applications and tools).
During the 360Giving Visualisation Challenge in 2018, we saw that many entries wrote code to fetch the information before transforming it into a relational database so it could be queried in more interesting ways. This meant people were duplicating work, and spent less time analysing and visualising grantmaking information overall.
Building resilient infrastructure
As a result, we decided to stop doing things manually and build an automated pipeline that fetches, checks and loads data into GrantNav on a daily basis. We also decided to make access to a relational database that can be queried using SQL — a standard language that many data scientists and researchers know how to use.
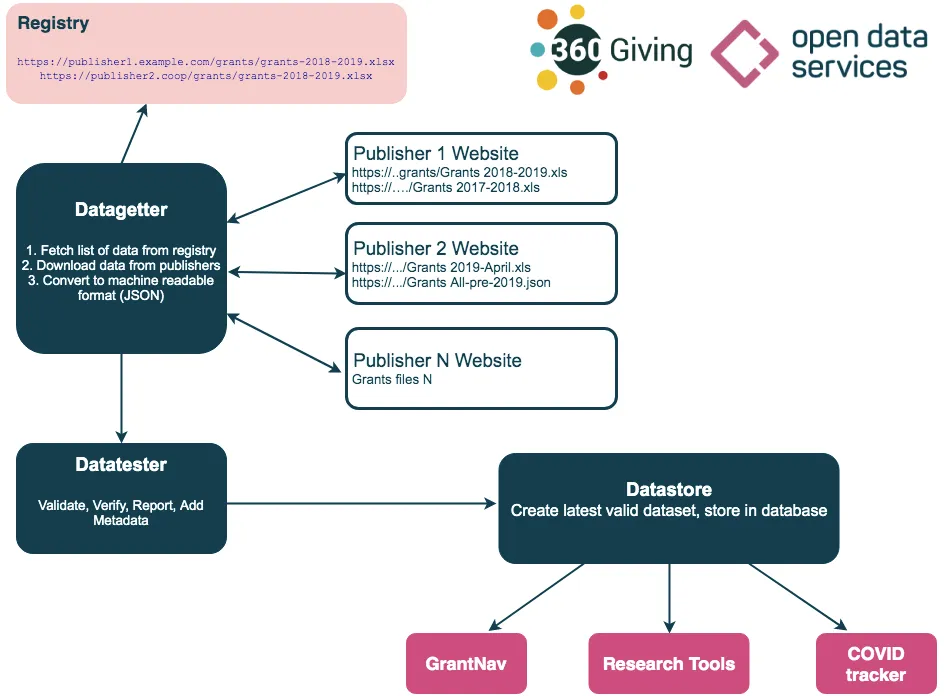
Our automated pipeline consists of three parts:
- a data getter which fetches the list from the registry, downloads published spreadsheets, and converts into JSON
- a data tester which validates, verifies, reports and adds metadata
- a data store which generates the latest valid dataset.
Automating loads
The pipeline is deliberately designed to be resilient.
We call the package the “latest valid dataset” because the datastore can automatically resolve any data integrity problems for up to a month, allowing 360Giving time to work with funders to resolve any issues.
As 360Giving data is published and distributed across funder’s websites, we’ve built in safeguards in case data becomes unavailable. If a website goes down or the page gets moved we are able to fill in the gaps by checking if we had the data before, and replacing the blank record with the last known good one.
We also built the pipeline to make maintenance more flexible. As GrantNav and the 360Giving data store are now not dependent on each other, we can make changes to one without affecting the others’ users.
Providing access to data
The datastore provides access to 360Giving data in the form of a relational database that is updated automatically on a daily basis. This work has massively decreased the path to building tools on top of 360Giving data, and means users are now able to query in more ways.
This ease of access meant that when 360Giving built their Covid grants tracker, fetching the data that powers it was as easy as writing an SQL query for a set of keywords, and running that query every morning after the datastore has updated. This allows for daily updates as new data is published. As well as providing data for GrantNav and COVID tracker, the datastore connects to Google Colab notebooks that we’ve developed to help prototype new tools and explore the data set.
What comes next
Working closely with 360Giving to understand their needs helped us to build resilient infrastructure that allows people to use data quickly and easily. This new automated pipeline both allows researchers better access to data, and frees up our time and space to make the data more useful for them.
In the future, we’ll keep working to understand 360Giving’s needs to improve and iterate on these systems, making 360Giving data more useful, usable and in use.