
Duncan Dewhurst heads up Open Data Services’ work on Open Contracting. He leads on working with the Open Contracting Partnership to support publishers and users of the Open Contracting Data Standard and to develop guidance, documentation and learning materials for the field. He also leads our work with CoST — the Infrastructure Transparency Initiative to develop and support the Open Contracting for Infrastructure Data Standard and he led our work with the World Bank on the Open Contracting Data Standard for Public Private Partnerships profile.
This blog post was first published by Open Contracting Partnership.
Over 30 different government agencies have now implemented the Open Contracting Data Standard. Most implementations have some things in common, but the context and constraints for each differ. As such, the technical choices made by each implementer also vary.
Our technical case studies report documents 5 different OCDS implementations.
The aim of the report is to provide insights into the technical choices made by implementers. The report also seeks to highlight the impact of these choices on data users. We hope this will be a useful resource for implementers wishing to learn from past experiences.
The case studies examine various aspects of each OCDS implementation, including:
-
Source systems
-
Solution architecture
-
Technology choice
-
Publication formats
-
Data access methods
-
Change history
-
Coverage of the OCDS schema
-
Data use and tools
### So what did we learn from studying these implementations?
Most implementations share a common high-level architecture, using a middleware component with an OCDS format datastore. This approach permits more flexibility than extracting and transforming data on demand and makes it easier to publish a change history.
Some implementations are event-based, i.e. they push data to an OCDS datastore whenever there is a change in the source system, such as a contract being awarded. Other implementations are pull-based, i.e. data is periodically extracted from the database of the source system.
Pull-based systems can be simpler to implement, but there is a risk of losing detail when source data changes multiple times between extractions. Counterintuitively, some pull-based implementations still achieve more timely publication than some event-based implementations.
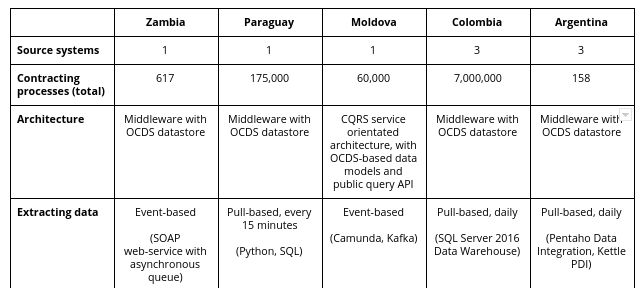
Extract from comparison table appendix\
In some cases, the source systems store data in JSON format, reducing the amount of transformation required. Other systems take a ‘SQL-first’ approach, in which data is extracted in tabular format before conversion to JSON format. The latter approach can be easier to maintain, depending on the skill-set of those responsible for maintenance.
All publishers provide a JSON API and most provide JSON bulk files too. Only some provide a search API and, for those that don’t, users may have to download all the data to find what they need.
Some publishers do not provide CSV or spreadsheet format data, which can create a barrier to use by less technical users.
Only some publishers provide a full change history, with others opting to publish only the latest information. Whilst publishing a change history can be a challenge, some types of analysis need it.
All publishers have created tools and visualizations based on their OCDS data. This is great to see, since using your own data helps to improve data quality.
For more detail and analysis you’ll need to read the report.
We’d love to hear your feedback on this resource so please feel free to comment in the report or send a message to data@open-contracting.org.