
In this blog post, we introduce Flatterer — a new tool that helps convert JSON into tabular data. To hear more about Flatterer, sign up to join David Raznick at the Frictionless Data Hangout on July 28th.
Open data needs to be available in formats people want to work with. In our experience at Open Data Services, we’ve found that developers often want access to structured data (for example, JSON) while analysts are used to working with flat data (in CSV files or tables).
More and more data is being published as JSON, but for most analysts this isn’t particularly useful. For many, working with JSON means needing to spend time converting the structured data into tables before they can get started.
That’s where Flatterer comes in. Flatterer is an opinionated JSON to CSV/XLSX/SQLITE/PARQUET converter. It helps people to convert JSON into relational, tabular data that can be easily analysed. It’s fast and memory efficient, and can be run either in the command line or as a Python library. The Python library supports creating data frames for all the flattened data, making it easy to analyse and visualise.
What does it do?
With Flatterer you can:
-
easily convert JSON to flat relational data such as CSV, XLSX, Database Tables, Pandas Dataframes and Parquet;
-
convert JSON into data packages, so you can use Frictionless data to convert into any database format;
-
create a data dictionary that contains metadata about the conversion, including fields contained in the dataset, to help you understand the data you are looking at;
-
create a new table for each one-to-many relationship, alongside _link fields that help to join the data together.
Why we built it
When you receive a JSON file where the structure is deeply nested or not well specified, it’s hard to determine what the data contains. Even if you know the JSON structure, it can still be time consuming to work out how to flatten the JSON into a relational structure for data analysis, and to be part of a data pipeline.
Flatterer aims to be the first tool to go to when faced with this problem. Although you may still need to handwrite code, Flatterer has a number of benefits over most handwritten approaches:
-
it’s fast — written in Rust but with Python bindings for ease of use. It can be 10x faster than hand written Python flattening;
-
it’s memory efficient — flatterer uses a custom streaming JSON parser which means that a long list of objects nested with the JSON will be streamed, so less data needs to be loaded into memory at once;
-
it gives you fast, memory efficient output to CSV/XLSX/SQLITE/PARQUET;
-
it uses best practice that has been learnt from our experience flattening JSON countless times, such as generating keys to link one-to-many tables to their parents.
Using Flatterer in the Open Ownership data pipeline
As an example, we’ve used Flatterer to help Open Ownership create a data pipeline to make information about who owns and controls companies available in a variety of data formats. In the example below, we’ve used Flatterer to convert beneficial ownership data from the Register of Enterprises of the Republic of Latvia and the OpenOwnership Register from JSON into CSV, SQLite, Postgresql, Big Query and Datasette formats.

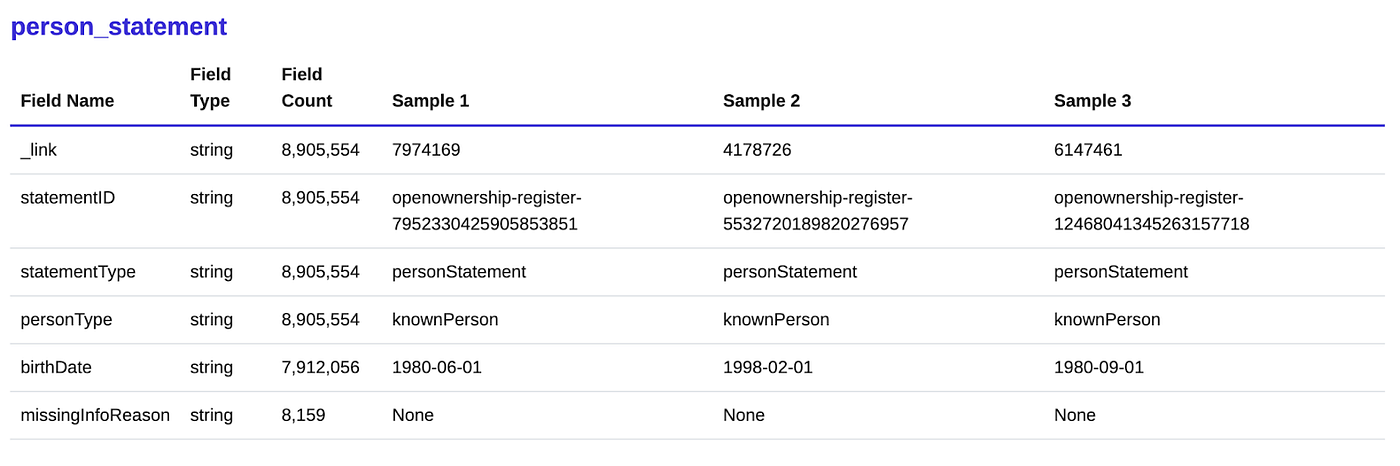
Alongside converting the data into different formats, Flatterer has created a data dictionary that shows the fields contained in the dataset, alongside the field type and field counts. In the example below, we show how this dictionary interprets person_statement fields contained in the Beneficial Ownership Data Standard.
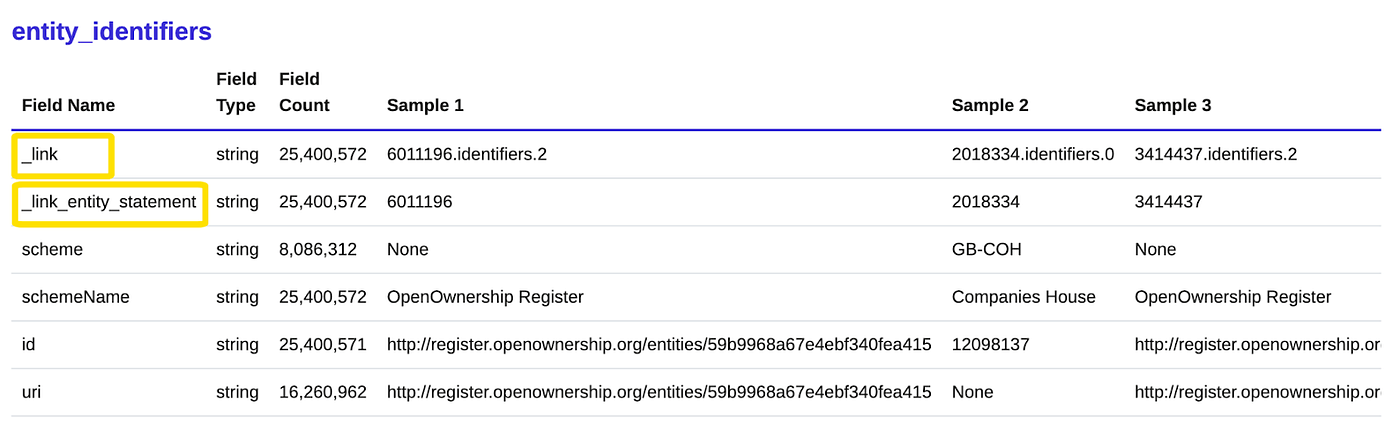
Finally, you can see Flatterer has created special _link fields, to help with joining the tables together. The example below shows how the _link field helps join entity identifiers to statements about beneficial ownership.
What’s next?
Next, we’ll be working to make Flatterer more user friendly. We’ll be exploring creating a desktop interface, improving type guessing for fields, and giving more summary statistics about the input data. We welcome feedback on the tool through GitHub, and are really interested to find out what kind of improvements you’d like to see.
More information about using Flatterer is available on Deepnote. To hear more about Flatterer, you can join David Raznick at Frictionless Data’s monthly community call on July 28th.