
Joining up datasets can be tricky, even when you’re working with standardised data.
One challenge that we often face is being sure something in one dataset is the same as (or different to) something in another. In other words, how can we unambiguously identify something that is being represented?
One way of simplifying this problem is to include identifiers as common element(s) that appear across datasets making them easier to combine. A good identifier draws on an external list, ideally an official source like a government register. It should be machine readable, unique and permanent. It should also contain within itself a reference to the list that it draws from.
In this blog post, we’ll explore what makes a good identifier, why we need to use them, and how they enable us to easily link datasets, using sample data from the Open Contracting Data Standard and Beneficial Ownership Data Standard as an example.
Why organisational identifiers matter
The Org-id.guide was created by a partnership of open data standards groups in order to fill a gap in our shared data infrastructure — open, interoperable and unambiguous identifiers for organisations across the globe. We’ll use our co-operative as an example of how it works.
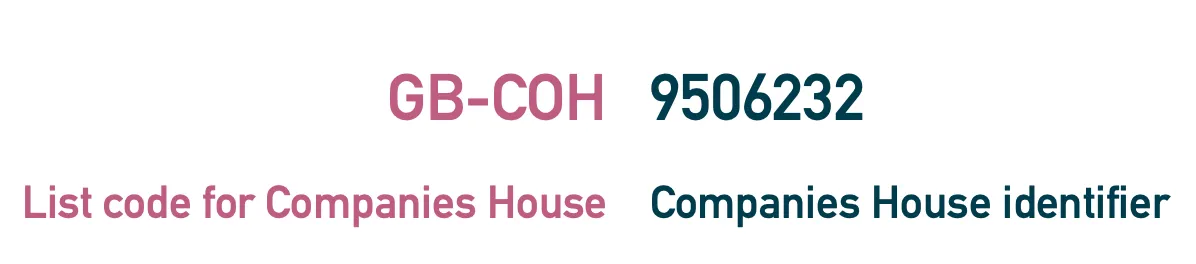
Open Data Services Co-operative is registered at Companies House in England and Wales. The Companies House database has assigned us the company number 09506232. Within the context of the Companies House dataset this identifier is unique — it’s enough to identify our co-operative alone.

When you need to start combining lists of organisations across multiple registers things get more difficult. There is a risk that another organisation listed on a different register may also use the identifier 09506232. In this context, we can’t be confident that the Companies House identifier alone can unambiguously refer to our co-op.
How org-id helps create consistent identifiers
The org-id list provides a mechanism to generate unique identifiers and avoid clashes. It does so by giving each organisation register an org-id code, and using this code as a prefix for existing identifiers to form a new identifier we can be sure is unique.
For example, within org-id our co-operative can be uniquely identified using the identifier of GB-COH-09506232.
Using this system, Org-id can provide unique identifiers for companies, charities, government agencies and other kinds of organisations — no matter where they are registered.
Clarifying ambiguities in a single dataset
The Open Contracting Data Standard (OCDS) provides a structured way of representing public procurement processes. Working with the data, we’ve found that when people are given a free text field, they will likely enter the name of a company in different ways.
The sample data below shows a simplified contracting process with two bidders.
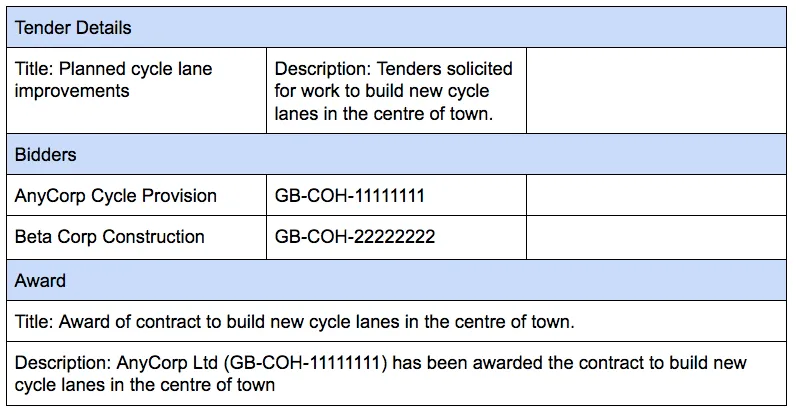
In the table above, the company with the identifier GB-COH-11111111 is referred to by two different names. As a bidder, the company is named as “AnyCorp Cycle Provision”, whereas the award description refers to this company as “AnyCorp Ltd”. Without an identifier, we can’t be sure that these are the same company.
The discrepancy in the procurement data could also be due to different parties entering information at different points in a contracting process. For example, the company might have entered their name as ‘AnyCorp Cycle Provision’ when they were applying for the tender. In contrast, when the award is published, the description is often written by the organisation in charge of procurement — in this example a local authority.
The difference might be because the companies are registered with one name, and trade with another; the company might have changed their registered name; someone might have made a mistake when entering the data into the procurement system.
Whatever the cause, without an identifier we can’t unambiguously assert that these names represent the same thing. Including identifiers means that we can.
Using identifiers also means we can record data in a way that is both human and machine readable so it can be analysed — even when there are spelling mistakes or data entry errors.
When you have good identifiers it’s much easier to find links between datasets
The Beneficial Ownership Data Standard (BODS) provides a structured way of representing ownership and control of companies and other legal entities. Linking this dataset to Open Contracting data provides opportunities to improve procurement processes and beneficial ownership data collection.
When combining open contracting and beneficial ownership data, organisational identifiers act as a glue that allows us to link information about legal entities together.
In the procurement data above, the company with the identifier GB-COH-11111111 is listed as both ‘AnyCorp Cycle Provision’ and ‘AnyCorp Ltd’. In the sample Ownership or Control Statement below, the same company is named as ‘AnyCorp Cycle Provision Ltd’.
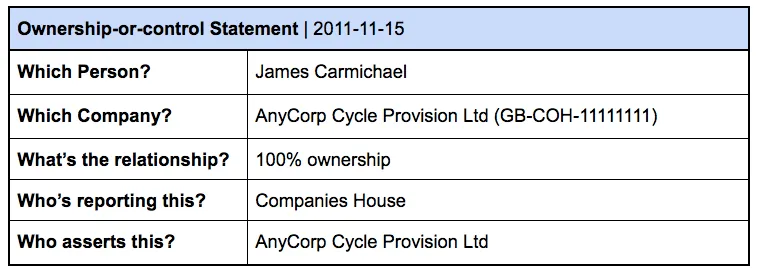
If we tried matching the record above to the names of the company in the procurement data alone, we wouldn’t be able to unambiguously assert that these two datasets refer to the same thing. It’s only because we’ve used consistent identifiers that we can be certain both reference the same company — and that these two records can be linked.
Linking these records means the local authority is able to clarify that GB-COH-11111111 won the bid, and the sole beneficial owner of that company is James Carmichael.
The examples we’ve described above show how identifiers can safeguard against genuine data entry errors, and enable us to easily link between datasets. Creating these links also has benefits for identifying risk, improving processes and strengthening safeguards against corruption.